| |
|
||||||||||
Wichtiger Hinweis:
Diese Website wird in älteren Versionen von Netscape ohne graphische Elemente dargestellt. Die Funktionalität der Website ist aber trotzdem gewährleistet. Wenn Sie diese Website regelmässig benutzen, empfehlen wir Ihnen, auf Ihrem Computer einen aktuellen Browser zu installieren. Weitere Informationen finden Sie auf
folgender Seite.
Important Note:
The content in this site is accessible to any browser or Internet device, however, some graphics will display correctly only in the newer versions of Netscape. To get the most out of our site we suggest you upgrade to the latest Netscape.
More information

In the PISA context a search algorithm is a method which tries to find solutions to a given problem by iterating three steps: the evaluation of candidate solutions, the selection of promising candidates based on this evaluation and the generation of new candidates by variation of these selected candidates. As examples most evolutionary algorithms and simulated annealing fall into this category.
PISA is mainly dedicated to multi-objective search, where the optimization problem is characterized by a set of conflicting goals and not just one criterion that needs to be optimized.
PISA consists of two parts:
PISA Performance Assessment is based on the above concept of separating the optimization process into the optimization problem and the selection process. It extends it by a set of statistical tools that allow to assess and compare different optimization methods..
A module on the selection side can be freely combined with any module on the problem side and vice versa. All modules can be made available as ready-to-use binaries.
PISA is a text-based interface for search algorithms. It splits an optimization process into two modules.
This partitioning is shown in the figure below:

All the problem specific parts are located
in the problem module, the Variator. In the selection module Selector a candidate solution
(called an individual) can be represented by an identifier (ID) and a set of
objective values describing the quality of this individual. This is
the only information passed from the problem module to the selection
module.
The problem module (Variator) creates an initial collection of individuals and
calculates the objective values. The selection module (Selector) then chooses a
collection of parent individuals which it thinks are promising. The
problem module variates these individuals in order to get a new
collection of offspring individuals. The selection module again
chooses the parents and so on. All this data exchange is established
using text files. The synchronization of the two modules is achieved
by writing a state variable into a text file which both programs can
read and update. The modules can be programmed in different programming
languages or even run on different (distributed) platforms.
PISA contains also libraries of state-of-the-art and ready-to-go selectors and a set of benchmark variators, see the corresponding library page.
The purpose of PISA PA is to support the algorithm expert in testing and comparing new multi-objective optimization algorithms on different test problems and real-world problems. With PISA PA, he can reliably compare different algorithms on benchmark problems using appropriate indicators and statistical methods. To this end, the communication between the Variator and Selector module is controlled and observed by a Monitor module, see the figure below:
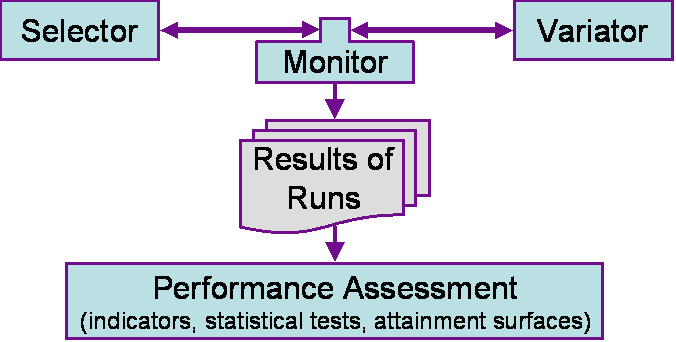
Objective values from various runs are collected in text files which are then further processed by
Together with the library of selectors (such as NSGA-II, SPEA2 and IBEA) and variators (benchmark problems), reliable performance assessment of multi-objective optimizers is made easy. For further information, look at the PISA PA page.
For more information about the architecture and specification of PISA and PISA PA consult the documentation page.

")